需求
(注:以下举例不包含任何恶意行为,如有不适请予以指正)
前几天帮朋友写一个爬虫,给出一些公司的code和公司高管姓名,要求爬取对应高管的一些公开信息,我们打开新浪财经网,先手动操作这个过程,首先是首页搜索框输入公司代码如000021
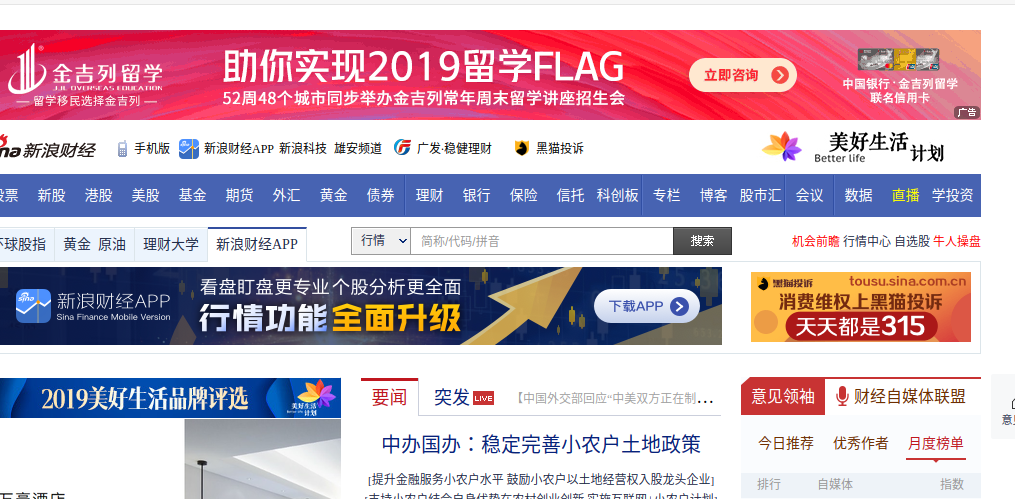
然后打开一个新的页面,这里我们点击进入公司页面
这里公司界面左下方我们找到公司高管的链接
之后进入公司高管页面
再之后就是搜索到对应的姓名点击链接进入并搜集需要的信息
初次实现
起初是打算用urllib之类的很底层的库来模拟get和post之类的过程而不打算使用浏览器,后来看网站的网络请求过程比较复杂于是就入坑了selenium
第一次使用selenium,由于是在家里只能百度搜索(吐槽下百度各种广告和搜不到)还有各种原因看不了官网文档,于是跟着网上的大部分博客写了个简单粗暴的版本
首先selenium的浏览器可以选择phantomjs,chrome,firefox,这里由于不想折腾太多环境问题,我就选择了chrome
环境配置
首先查看chrome版本,在浏览器标签栏输入chrome://version查看浏览器版本信息

然后对应如下表格找到对应chromeDriver版本下载安装
| chromeDriver版本 | chrome版本 |
|---|---|
| v2.43 | v69-71 |
| v2.42 | v68-70 |
| v2.41 | v67-69 |
| v2.40 | v66-68 |
| v2.39 | v66-68 |
| v2.38 | v65-67 |
| v2.37 | v64-66 |
| v2.36 | v63-65 |
| v2.35 | v62-64 |
| v2.33 | v60-62 |
| v2.32 | v59-61 |
| v2.31 | v58-60 |
| v2.30 | v58-60 |
| v2.29 | v56-58 |
| v2.28 | v55-57 |
| v2.27 | v54-56 |
| v2.26 | v53-55 |
| v2.25 | v53-55 |
| v2.24 | v52-54 |
| v2.23 | v51-53 |
| v2.22 | v49-52 |
| v2.21 | v46-50 |
| v2.20 | v43-48 |
| v2.19 | v43-47 |
| v2.18 | v43-46 |
| v2.17 | v42-43 |
| v2.13 | v42-45 |
| v2.15 | v40-43 |
| v2.14 | v39-42 |
| v2.13 | v38-41 |
| v2.12 | v36-40 |
| v2.11 | v36-40 |
| v2.10 | v33-36 |
| v2.9 | v31-34 |
| v2.8 | v30-33 |
| v2.7 | v30-33 |
| v2.6 | v29-32 |
| v2.5 | v29-32 |
| v2.4 | v29-32 |
这边是chromedriver的链接
接下来安装selenium(我的机子python2和3都装了,只装了3的可以只敲pip)1
pip3 install selenium
初次搬砖
selenium的API参考官方说明
这边列举下常用接口(转自https://www.cnblogs.com/yufeihlf/p/5764807.html)
可用driver:
- phantomjs
- chrome
- firefox
常用变量:
- driver.current_url:用于获得当前页面的URL
- driver.title:用于获取当前页面的标题
- driver.page_source:用于获取页面html源代码
- driver.current_window_handle:用于获取当前窗口句柄
- driver.window_handles:用于获取所有窗口句柄
常用函数:
- driver.find_element*():定位元素
- driver.get(url):浏览器加载url。
实例:driver.get(“http//:www.baidu.com") - driver.forward():浏览器向前(点击向前按钮)。
- driver.back():浏览器向后(点击向后按钮)。
- driver.refresh():浏览器刷新(点击刷新按钮)。
- driver.close():关闭当前窗口,或最后打开的窗口。
- driver.quit():关闭所有关联窗口,并且安全关闭session。
- driver.maximize_window():最大化浏览器窗口。
- driver.set_window_size(宽,高):设置浏览器窗口大小。
- driver.get_window_size():获取当前窗口的长和宽。
- driver.get_window_position():获取当前窗口坐标。
- driver.get_screenshot_as_file(filename):截取当前窗口。
实例:driver.get_screenshot_as_file(‘D:/selenium/image/baidu.jpg’) - driver.implicitly_wait(秒):隐式等待,通过一定的时长等待页面上某一元素加载完成。
若提前定位到元素,则继续执行。若超过时间未加载出,则抛出NoSuchElementException异常。
实例:driver.implicitly_wait(10) #等待10秒 - driver.switch_to_frame(id或name属性值):切换到新表单(同一窗口)。若无id或属性值,可先通过xpath定位到iframe,再将值传给switch_to_frame()
- driver.switch_to.parent_content():跳出当前一级表单。该方法默认对应于离它最近的switch_to.frame()方法。
- driver.switch_to.default_content():跳回最外层的页面。
- driver.switch_to_window(窗口句柄):切换到新窗口。
- driver.switch_to.window(窗口句柄):切换到新窗口。
- driver.switch_to_alert():警告框处理。处理JavaScript所生成的alert,confirm,prompt.
- driver.switch_to.alert():警告框处理。
- driver.execute_script(js):调用js。
- driver.get_cookies():获取当前会话所有cookie信息。
- driver.get_cookie(cookie_name):返回字典的key为“cookie_name”的cookie信息。
实例:driver.get_cookie(“NET_SessionId”) - driver.add_cookie(cookie_dict):添加cookie。“cookie_dict”指字典对象,必须有name和value值。
- driver.delete_cookie(name,optionsString):删除cookie信息。
- driver.delete_all_cookies():删除所有cookie信息。
至于元素的搜索有tag_name,xpath,id等多种方式,这里不一一列举,详见文档
首先是浏览器的打开,这里用的是chrome引擎1
2
3browser = webdriver.Chrome()
url = 'https://finance.sina.com.cn/'
browser.get(url)
然后是关于超时加载的问题,这里我由于网速慢我设置了较长的等待时间等到一些元素加载完再执行js脚本让浏览器停止加载全部页面
1 | def openHomePage(browser,url): |
之后就是按要求搜索到对应html元素并且执行对应操作,,就是各种find_element然后click或者send_key,然后控制一下sleep来等待加载网页元素防止报错元素不存在即还未加载完这里就不一一贴代码了,后面会放代码链接
这里有一个用于切换tab页面的可以看一下
1 | def switch_handle(handles,current_handle): |
第一次搬砖过程中由于是第一次入坑selenium而且有点小偷懒,于是GUI也没关,就用上面那个步骤把输入文件读入后for了一下暴力解决,结果显而易见龟速爬虫,于是后面朋友还是类似操作的爬虫要求我进行了优化
进行优化
由于初次搬砖结果一般般,然后我开始考虑优化,首先一个是使用了GUI然后速度太慢,第二个由于等待加载过程什么也没做cpu空闲着可以考虑用多线程优化,第三个通过分析网页链接可以知道公司高管界面的url有一定规律,直接get这个界面省去前面的操作
关于无头浏览器,一开始我是去直接安装phantomjs但是遇到各种坑后面发现selenium后面不支持phantomjs了,有些接口是没维护的,于是后来使用了chrome的无头模式,也不会慢多少
无头模式可以在生成driver对象的时候填入chrome_options进行设置,下面代码顺便设置了一些service_args用来禁用一些图片加载和忽略一些网络错误以及启用浏览器cache
1 | chrome_options = Options() |
关于多线程,这部分经历了一定的思考过程,由于不同线程之间的互斥访问资源,最后想到使用循环队列来解决这个问题,这里我写了一个类用来实现这部分功能
1 | class conChrome: |
然后在类里面写一个getPage函数,get一个driver出队列,操作完put回去队列尾部,具体代码就不贴全部了给关键操作后面有链接
1 | def getPage(url): |
最后是main里面创建多线程
1 | cur = conChrome() |